
Differential Transformer
This post presents a new architecture for large language models (LLMs) known as the Differential Transformer (DIFF Transformer), which improves upon traditional transformers by addressing the issue of “attention noise”. [1-3] Attention noise refers to the tendency of transformers to allocate attention to irrelevant parts of the input, hindering their ability to accurately retrieve key information. [4-6] This can lead to problems such as inaccurate outputs, hallucinations (generating responses that are logically or factually incorrect), and slower processing times. [2, 3]
The Differential Attention Mechanism
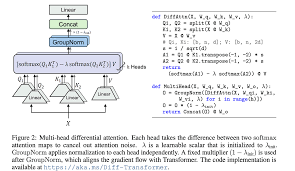
DIFF Transformer tackles this challenge by incorporating a differential attention mechanism. [1, 7, 8] This mechanism, inspired by noise-canceling headphones and differential amplifiers, computes two separate softmax attention maps and then subtracts them to filter out noise. [9-11] This subtraction process amplifies attention to relevant tokens while suppressing irrelevant ones, improving the signal-to-noise ratio. [1, 12, 13]
Traditional transformers, in contrast, rely on a single softmax attention map, which can lead to important content being overshadowed by irrelevant context, particularly in long and complex inputs. [14, 15]
Key Advantages of DIFF Transformer
The sources highlight several key advantages of the DIFF Transformer over traditional transformers:
- Improved Scalability: DIFF Transformer achieves comparable or superior performance with significantly fewer parameters (65% fewer) and training tokens (36% fewer). [16-18] This makes it more efficient and cost-effective to train large language models. [18, 19]
- Superior Long-Context Handling: While traditional transformers struggle with longer inputs, DIFF Transformer maintains consistent performance across extended sequences, effectively leveraging long contexts. [19-21] This makes it suitable for applications involving lengthy texts, such as book summarization or legal document analysis. [20-22]
- Enhanced Key Information Retrieval: By canceling out attention noise, DIFF Transformer exhibits higher accuracy in key information retrieval tasks, particularly in situations with multiple distractions (multi-needle retrieval). [22-24] In one experiment, DIFF Transformer achieved a 30% improvement in accuracy over traditional transformers when six “needles” of information were present. [23, 25]
- Mitigation of Hallucinations: DIFF Transformer’s noise-canceling mechanism helps to reduce the risk of generating hallucinated or irrelevant responses. [26-28] This leads to improved performance in tasks like summarization and question answering, where factual consistency is paramount. [27-29]
- Robust In-Context Learning: Unlike traditional transformers, which can experience performance drops when the order of input examples is changed, DIFF Transformer demonstrates robust performance regardless of input order. [30-32]
- Minimal Activation Outliers (Better for Quantization): DIFF Transformer produces fewer extreme activations, making it more suitable for low-bit quantization without performance degradation. [33-35] Even with 4-bit quantization, it outperforms traditional transformers, making it ideal for deployment on resource-constrained devices. [34-36]
- Consistent Performance with FlashAttention: DIFF Transformer seamlessly integrates with FlashAttention, a memory-efficient algorithm that accelerates transformer computations. [37-39] While it does introduce a slight computational overhead, the gain in accuracy and efficiency outweighs this minor cost. [39-41]
Conclusion
The sources suggest that the DIFF Transformer represents a significant advancement in transformer architecture, offering a more efficient, accurate, and robust alternative to traditional transformers. Its novel differential attention mechanism addresses the problem of attention noise, leading to improved performance in various tasks, particularly those involving long contexts, key information retrieval, and hallucination mitigation.